[ English | Indonesia | русский ]
Масштабирование MariaDB и RabbitMQ¶
OpenStack — это облачная вычислительная платформа, разработанная с учетом высокой масштабируемости. Однако, несмотря на то что OpenStack разработан с учетом масштабируемости, при крупных развертываниях могут возникнуть некоторые потенциальные узкие места. Эти узкие места обычно связаны с производительностью и пропускной способностью кластеров RabbitMQ и MariaDB.
RabbitMQ — это брокер сообщений, который используется для разделения различных компонентов OpenStack. MariaDB — это база данных, которая используется для хранения данных OpenStack. Если эти два компонента работают неэффективно, это может негативно повлиять на производительность всего развертывания OpenStack.
Существует ряд различных методологий, которые можно использовать для повышения производительности кластеров RabbitMQ и MariaDB. Эти методологии включают в себя масштабирование кластеров, использование другого брокера сообщений или базы данных, а также оптимизацию конфигурации кластеров.
В этой серии статей будут рассмотрены потенциальные узкие места, которые могут возникнуть при развертывании крупных инсталляций OpenStack, а также способы масштабирования для повышения производительности кластеров RabbitMQ и MariaDB.
Примечание
Примеры, приведенные в данной документации, были созданы на OpenStack 2023.1 (Antelope). Такие же шаги можно реализовать и в более ранних версиях, но для этого могут потребоваться дополнительные этапы или несколько иные настройки.
Наиболее распространенное развертывание¶
Прежде чем говорить о способах улучшения ситуации, давайте кратко опишем «исходную точку», чтобы понять, с чем мы имеем дело на начальном этапе.
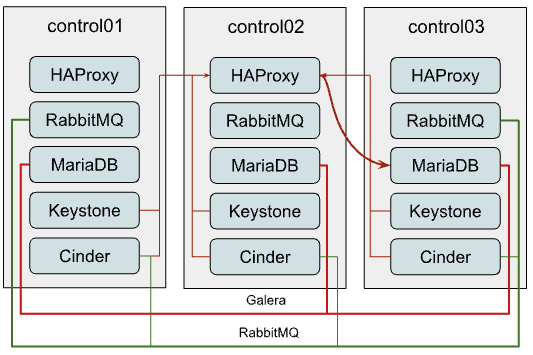
Наиболее распространенная схема развертывания OpenStack-Ansible состоит из трех управляющих (control) узлов, каждый из которых запускает все службы API OpenStack вместе с поддерживающей инфраструктурой, такой как кластеры MariaDB и RabbitMQ. Это хорошая отправная точка для развертываний небольшого и среднего масштаба. Однако, по мере роста развертывания могут начать возникать проблемы с производительностью. Обычно связь между службами и MySQL/RabbitMQ выглядит следующим образом:
MariaDB
Как видно на схеме, все подключения к MariaDB проходят через HAProxy, который имеет внутренний виртуальный IP-адрес (VIP). OpenStack-Ansible настраивает кластер Galera для MariaDB, который представляет собой систему репликации с несколькими мастерами. Хотя вы можете отправлять любой запрос любому участнику кластера, все запросы на запись будут передаваться текущему «основному» инстансу, создавая больше внутреннего трафика и увеличивая объем работы, которую должен выполнять каждый инстанс. Поэтому рекомендуется передавать запросы на запись только «основному» инстансу.
Однако HAProxy не способен балансировать запросы MySQL на уровне приложения (L7 модели OSI), чтобы разделить запросы на чтение и запись, поэтому нам приходится балансировать TCP-потоки (L3) и передавать весь трафик без какого-либо разделения на текущий «основной» узел в кластере Galera, что создает потенциальное узкое место.
RabbitMQ
RabbitMQ кластеризуется по-другому. Мы предоставляем клиентам IP-адреса всех участников кластера, и клиент сам решает, какой бэкенд он будет использовать для взаимодействия. Только интерфейс управления RabbitMQ балансируется через haproxy, поэтому подключение клиентов к очередям никоим образом не зависит от HAProxy.
Хотя использование HA-очередей и даже кворумных очередей приводит к тому, что все сообщения и очереди дублируются на всех или нескольких участников кластера. Несмотря на то, что кворумные очереди демонстрируют гораздо лучшую производительность, они по-прежнему страдают от кластерного трафика, который при определенном масштабе по-прежнему становится проблемой.
Вариант 1: независимые кластеры для каждой службы¶
При таком подходе вы можете предоставить наиболее загруженным службам, таким как Nova или Neutron, отдельные кластеры MariaDB и RabbitMQ. Эти новые кластеры могут находиться на отдельном оборудовании.
В приведенном ниже примере мы предполагаем, что только Neutron переконфигурируется для использования нового автономного кластера, в то время как другие службы продолжают использовать уже существующий кластер. Таким образом, подключение Neutron будет выглядеть следующим образом:
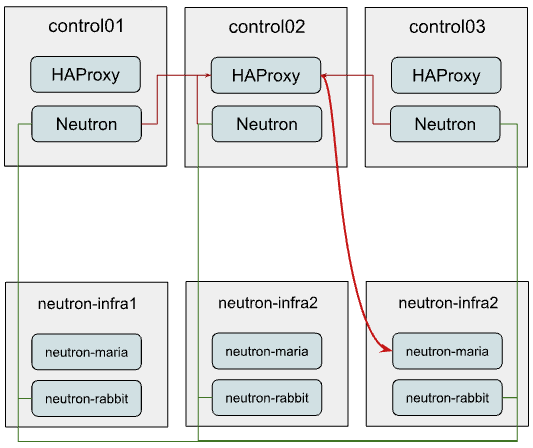
Как вы могли заметить, мы по-прежнему используем тот же инстанс HAProxy для балансировки MariaDB в новом инфраструктурном кластере.
Далее мы опишем, как настроить такой стек и выполнить переход службы на эту новую структуру.
Настройка новых кластеров MariaDB и RabbitMQ¶
Чтобы настроить такую конфигурацию и перенести Neutron с ее использованием с помощью OpenStack-Ansible, необходимо выполнить следующие действия:
Примечание
Для более глубокого понимания того, как должны быть построены файлы env.d и conf.d, вы можете обратиться к следующей документации: Понимание inventory
Определите новые группы для RabbitMQ и MariaDB. Для этого можно создать файлы со следующим содержанием:
/etc/openstack_deploy/env.d/galera-neutron.yml:
# env.d file are more clear if you read them bottom-up
# At component skeleton you map component to ansible groups
component_skel:
# Component itself is an ansible group as well
neutron_galera:
# You tell in which ansible groups component will appear
belongs_to:
- neutron_galera_all
- galera_all
# At container skeleton you link components to physical layer
container_skel:
neutron_galera_container:
# Here you define on which physical hosts container will reside
belongs_to:
- neutron-database_containers
# Here you define which components will reside on container
contains:
- neutron_galera
# At physical skeleton level you map containers to hosts
physical_skel:
# Here you tell to which global group containers will be added
# from the host in question.
# Please note, that <name>_hosts and <name>_containers are
# interconnected, and <name> can not contain underscores.
neutron-database_containers:
belongs_to:
- all_containers
# You define `<name>_hosts` in your openstack_user_config or conf.d
# files to tell on which physical hosts containers should be spawned
neutron-database_hosts:
belongs_to:
- hosts
/etc/openstack_deploy/env.d/rabbit-neutron.yml:
# env.d file are more clear if you read them bottom-up
# At component skeleton you map component to ansible groups
component_skel:
# Component itself is an ansible group as well
neutron_galera:
# You tell in which ansible groups component will appear
belongs_to:
- neutron_galera_all
- galera_all
# At container skeleton you link components to physical layer
container_skel:
neutron_galera_container:
# Here you define on which physical hosts container will reside
belongs_to:
- neutron-database_containers
# Here you define which components will reside on container
contains:
- neutron_galera
# At physical skeleton level you map containers to hosts
physical_skel:
# Here you tell to which global group containers will be added
# from the host in question.
# Please note, that <name>_hosts and <name>_containers are
# interconnected, and <name> can not contain underscores.
neutron-database_containers:
belongs_to:
- all_containers
# You define `<name>_hosts` in your openstack_user_config or conf.d
# files to tell on which physical hosts containers should be spawned
neutron-database_hosts:
belongs_to:
- hosts
/etc/openstack_deploy/env.d/rabbit-neutron.yml:
# On the component level we are creating group `neutron_rabbitmq`
# that is also part of `rabbitmq_all` and `neutron_rabbitmq_all`
component_skel:
neutron_rabbitmq:
belongs_to:
- rabbitmq_all
- neutron_rabbitmq_all
# On the container level we tell to create neutron_rabbitmq on
# neutron-mq_hosts
container_skel:
neutron_rabbit_mq_container:
belongs_to:
- neutron-mq_containers
contains:
- neutron_rabbitmq
# We define the physical level as a base level which can be consumed
# by container and component skeleton.
physical_skel:
neutron-mq_containers:
belongs_to:
- all_containers
neutron-mq_hosts:
belongs_to:
- hosts
Сопоставьте ваши новые хосты neutron-infra с этими новыми группами. Добавьте в файл openstack_user_config.yml следующее содержимое:
neutron-mq_hosts: &neutron_infra
neutron-infra1:
ip: 172.29.236.200
neutron-infra2:
ip: 172.29.236.201
neutron-infra3:
ip: 172.29.236.202
neutron-database_hosts: *neutron_infra
Определите некоторые конкретные конфигурации для вновь созданных групп и сбалансируйте их:
MariaDB
В файле
/etc/openstack_deploy/group_vars/neutron_galera.yml:galera_cluster_members: "{{ groups['neutron_galera'] }}" galera_cluster_name: neutron_galera_cluster galera_root_password: mysecret
В файле /etc/openstack_deploy/group_vars/galera.yml:
galera_cluster_members: "{{ groups['galera'] }}"
Переместите galera_root_password из
/etc/openstack_deploy/user_secrets.ymlв/etc/openstack_deploy/group_vars/galera.ymlRabbitMQ
В файле
/etc/openstack_deploy/group_vars/neutron_rabbitmq.yml:
rabbitmq_host_group: neutron_rabbitmq rabbitmq_cluster_name: neutron_cluster
В файле /etc/openstack_deploy/group_vars/rabbitmq.yml
rabbitmq_host_group: rabbitmq
HAProxy В
/etc/openstack_deploy/user_variables.ymlопределите дополнительную службу для MariaDB:haproxy_extra_services: - haproxy_service_name: galera_neutron haproxy_backend_nodes: "{{ (groups['neutron_galera'] | default([]))[:1] }}" haproxy_backup_nodes: "{{ (groups['neutron_galera'] | default([]))[1:] }}" haproxy_bind: "{{ [haproxy_bind_internal_lb_vip_address | default(internal_lb_vip_address)] }}" haproxy_port: 3307 haproxy_backend_port: 3306 haproxy_check_port: 9200 haproxy_balance_type: tcp haproxy_stick_table_enabled: False haproxy_timeout_client: 5000s haproxy_timeout_server: 5000s haproxy_backend_options: - "httpchk HEAD / HTTP/1.0\\r\\nUser-agent:\\ osa-haproxy-healthcheck" haproxy_backend_server_options: - "send-proxy-v2" haproxy_allowlist_networks: "{{ haproxy_galera_allowlist_networks }}" haproxy_service_enabled: "{{ groups['neutron_galera'] is defined and groups['neutron_galera'] | length > 0 }}" haproxy_galera_service_overrides: haproxy_backend_nodes: "{{ groups['galera'][:1] }}" haproxy_backup_nodes: "{{ groups['galera'][1:] }}"
Подготовьте новые инфраструктурные хосты и создайте на них контейнеры. Для этого выполните команду:
# openstack-ansible playbooks/setup-hosts.yml --limit neutron-mq_hosts,neutron-database_hosts,neutron_rabbitmq,neutron_galera
Разверните кластеры:
MariaDB:
openstack-ansible playbooks/galera-install.yml --limit neutron_galeraRabbitMQ:
openstack-ansible playbooks/rabbitmq-install.yml --limit neutron_rabbitmq
Перенос службы для использования новых кластеров¶
Хотя использовать новый кластер RabbitMQ для службы относительно просто, миграция базы данных является более сложной задачей и потребует некоторого времени простоя.
Сначала нам нужно сообщить Neutron, что отныне база данных MySQL для службы будет прослушивать другой порт. Для этого добавьте следующее переопределение в файл user_variables.yml:
neutron_galera_port: 3307
Теперь давайте подготовим базу данных назначения: создадим саму базу данных вместе с необходимыми пользователями и предоставим им права на взаимодействие с базой данных. Для этого мы запустим роль neutron с тегом common-db и ограничим выполнение только группой neutron_server. Для этого можно использовать следующую команду:
# openstack-ansible playbooks/os-neutron-install.yml --limit neutron_server --tags common-db
После подготовки базы данных необходимо отключить бэкенды HAProxy, которые проксируют трафик к API служб, чтобы предотвратить любые действия пользователей или служб с ней.
Для этого мы используем небольшой пользовательский плейбук. Назовем его haproxy_backends.yml:
- hosts: haproxy_all
tasks:
- name: Manage backends
community.general.haproxy:
socket: /run/haproxy.stat
backend: "{{ backend_group }}-back"
drain: "{{ haproxy_drain | default(False) }}"
host: "{{ item }}"
state: "{{ haproxy_state | default('disabled') }}"
shutdown_sessions: "{{ haproxy_shutdown_sessions | default(False) | bool }}"
wait: "{{ haproxy_wait | default(False) | bool }}"
wait_interval: "{{ haproxy_wait_interval | default(5) }}"
wait_retries: "{{ haproxy_wait_retries | default(24) }}"
with_items: "{{ groups[backend_group] }}"
Мы запускаем его следующим образом:
# openstack-ansible haproxy_backends.yml -e backend_group=neutron_server
Нет, мы можем остановить службу API для Neutron:
# ansible -m service -a "state=stopped name=neutron-server" neutron_server
И запустить резервное копирование/восстановление базы данных MySQL для службы. Для этой цели мы будем использовать еще один небольшой плейбук, который мы назовем mysql_backup_restore.yml со следующим содержанием:
- hosts: "{{ groups['galera'][0] }}"
vars:
_db: "{{ neutron_galera_database | default('neutron') }}"
tasks:
- name: Dump the db
shell: "mysqldump --single-transaction {{ _db }} > /tmp/{{ _db }}"
- name: Fetch the backup
fetch:
src: "/tmp/{{ _db }}"
dest: "/tmp/db-backup/"
flat: yes
- hosts: "{{ groups['neutron_galera'][0] }}"
vars:
_db: "{{ neutron_galera_database | default('neutron') }}"
tasks:
- name: Copy backups to destination
copy:
src: "/tmp/db-backup/"
dest: "/tmp/db-backup/"
- name: Restore the DB backup
shell: "mysql {{ _db }} < /tmp/db-backup/{{ _db }}"
Теперь запустим только что созданный плейбук:
# openstack-ansible mysql_backup_restore.yml
Примечание
Вышеуказанный плейбук не является идемпотентным, так как он перезаписывает содержимое базы данных на хостах назначения.
После того, как содержимое базы данных находится на месте, мы можем перенастроить службу с помощью плейбука.
Это не только укажет Neutron использовать новую базу данных, но и переключит его на использование нового кластера RabbitMQ, а также повторно включит службу в HAProxy.
Для этого необходимо выполнить следующую команду:
# openstack-ansible playbooks/os-neutron-install.yml --tags neutron-config,common-mq
После завершения плейбука будут запущены службы neutron и настроены для использования новых кластеров.
Вариант 2: выделенное оборудование для кластеров¶
В этом разделе описывается, как перенести текущие кластеры MariaDB и RabbitMQ на отдельные узлы. Этот подход можно использовать для разгрузки плоскости управления (control plane) и предоставления выделенных ресурсов для кластеров.
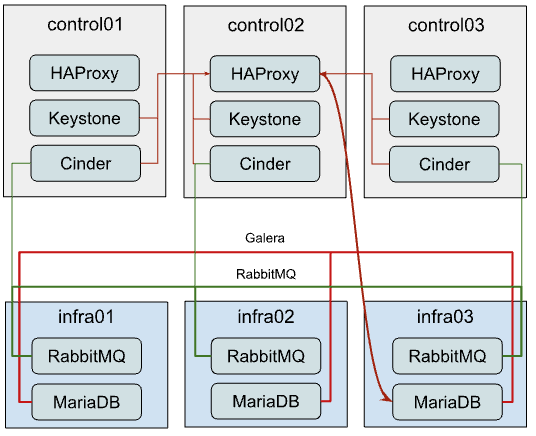
Хотя создать вышеуказанную архитектуру с самого начала развертывания довольно просто, безупречная миграция существующего развертывания на такую конфигурацию является более сложной задачей, поскольку необходимо перенести работающие кластеры на новое оборудование. Поскольку мы будем выполнять перенос по одному, чтобы сохранить как минимум два активных участника кластера, приведенные ниже шаги необходимо повторить для двух других участников.
Перенос MariaDB на новое оборудование¶
Первое, что нужно сделать, это перечислить текущих участников кластера MariaDB. Для этого можно выполнить следующую ad-hoc команду:
# cd /opt/openstack-ansible/
# ansible -m debug -a "var=groups['galera']" localhost
localhost | SUCCESS => {
"groups['galera']": [
"control01_galera_container-68e1fc47",
"control02_galera_container-59576533",
"control03_galera_container-f7d1b72b"
]
}
Если не указано иное, первый хост в группе считается «загрузочным». Этот загрузочный хост следует переносить последним, чтобы избежать ненужных переключений, поэтому рекомендуется начинать перенос хостов на новое оборудование с последнего по списку в выводе.
После того, как мы определили порядок выполнения, пришло время для пошагового руководства.
Удалите последний контейнер в группе с помощью следующего плейбука:
# openstack-ansible playbooks/lxc-containers-destroy.yml --limit control03_galera_container-f7d1b72b
Уберите удаленный контейнер из inventory:
# ./scripts/inventory-manage.py -r control03_galera_container-f7d1b72b
Перенастройте openstack_user_config, чтобы создать новый контейнер.
Предположим, что в настоящее время у вас есть конфигурация, подобная приведенной ниже, в файле openstack_user_config.yml:
_control_hosts: &control_hosts control01: ip: 172.29.236.11 control02: ip: 172.29.236.12 control03: ip: 172.29.236.13 shared-infra_hosts: *control_hosts
Преобразуйте его в нечто подобное:
_control_hosts: &control_hosts control01: ip: 172.29.236.11 control02: ip: 172.29.236.12 control03: ip: 172.29.236.13 memcaching_hosts: *control_hosts mq_hosts: *control_hosts operator_hosts: *control_hosts database_hosts: control01: ip: 172.29.236.11 control02: ip: 172.29.236.12 infra03: ip: 172.29.236.23
В приведенном выше примере мы разделяем каждую службу, входящую в состав shared-infra_hosts, и определяем их отдельно, а также указываем MariaDB новый хост назначения.
Создайте контейнер на новом инфраструктурном узле:
# openstack-ansible playbooks/lxc-containers-create.yml --limit infra03,galera
Примечание
Перед этим шагом необходимо подготовить новые инфраструктурные хосты (т. е. запустить на них плейбук
setup-hosts.yml).Установите MariaDB в этот новый контейнер и добавьте его в кластер:
# openstack-ansible playbooks/galera-install.yml
После завершения плейбука вы можете убедиться, что кластер находится в состоянии Synced и имеет правильный cluster_size, выполнив следующий ad-hoc:
# ansible -m command -a "mysql -e \"SHOW STATUS WHERE Variable_name IN ('wsrep_local_state_comment', 'wsrep_cluster_size', 'wsrep_incoming_addresses')\"" neutron_galera
Если кластер в рабочем состоянии, повторите шаги 1-6 для остальных инстансов, включая «загрузочный.
Перенос RabbitMQ на новое оборудование¶
Процесс миграции RabbitMQ будет практически таким же, как и в случае с MariaDB, за одним исключением — при переносе контейнеров на новое оборудование необходимо сохранить те же IP-адреса. В противном случае нам придется перенастраивать все службы (такие как cinder, nova, neutron и т. д.), которые также используют RabbitMQ, поскольку, в отличие от MariaDB, которая балансируется через HAProxy, здесь клиент сам решает, к какому бэкенду RabbitMQ он будет подключаться.
Таким образом, нам также не важен порядок миграции.
Поскольку нам необходимо сохранить IP-адрес, давайте соберем эти данные, прежде чем предпринимать какие-либо действия в отношении текущей настройки:
# ./scripts/inventory-manage.py -l | grep rabbitmq
| control01_rabbit_mq_container-a3a802ac | None | rabbitmq | control01 | None | 172.29.239.49 | None |
| control02_rabbit_mq_container-51f6cf7c | None | rabbitmq | control02 | None | 172.29.236.82 | None |
| control03_rabbit_mq_container-b30645d9 | None | rabbitmq | control03 | None | 172.29.238.23 | None |
Перед удалением контейнера RabbitMQ стоит перевести инстанс RabbitMQ в режим обслуживания, чтобы он мог переложить свои обязанности на других участников кластера и правильно закрыть соединения с клиентами. Для этого можно использовать следующую ad-hoc команду:
root@deploy:/opt/openstack-ansible# ansible -m command -a "rabbitmq-upgrade drain" control01_rabbit_mq_container-a3a802ac
control01_rabbit_mq_container-a3a802ac | CHANGED | rc=0 >>
Will put node rabbit@control01-rabbit-mq-container-a3a802ac into maintenance mode. The node will no longer serve any client traffic!
Теперь мы можем приступить к удалению контейнера:
# openstack-ansible playbooks/lxc-containers-destroy.yml --limit control01_rabbit_mq_container-a3a802ac
И удалите его из inventory:
# ./scripts/inventory-manage.py -r control01_rabbit_mq_container-a3a802ac
Теперь вам нужно перенастроить openstack_user_config аналогично тому, как это было сделано для MariaDB. Итоговая запись на этом этапе для RabbitMQ должна выглядеть следующим образом:
mq_hosts: infra01: ip: 172.29.236.21 control02: ip: 172.29.236.12 control03: ip: 172.29.236.13
Примечание
Убедитесь, что у вас не определено больше общих shared-infra_hosts.
Теперь нам нужно вручную пересоздать inventory и убедиться, что новая запись была связана с нашей инфраструктурой infra01:
# ./inventory/dynamic_inventory.py
...
# ./scripts/inventory-manage.py -l | grep rabbitmq
| control02_rabbit_mq_container-51f6cf7c | None | rabbitmq | control02 | None | 172.29.236.82 | None |
| control03_rabbit_mq_container-b30645d9 | None | rabbitmq | control03 | None | 172.29.238.23 | None |
| infra01_rabbit_mq_container-10ec4732 | None | rabbitmq | infra01 | None | 172.29.238.248 | None |
Как видно из приведенного выше вывода, была создана запись для нового контейнера и правильно назначена хосту infra01. Хотя этот контейнер имеет новый IP-адрес, нам необходимо сохранить его. Поэтому мы вручную заменили новый IP-адрес на старый в файле inventory и убедились, что теперь он правильный:
# sed -i 's/172.29.238.248/172.29.239.49/g' /etc/openstack_deploy/openstack_inventory.json
#./scripts/inventory-manage.py -l | grep rabbitmq
| control02_rabbit_mq_container-51f6cf7c | None | rabbitmq | control02 | None | 172.29.236.82 | None |
| control03_rabbit_mq_container-b30645d9 | None | rabbitmq | control03 | None | 172.29.238.23 | None |
| infra01_rabbit_mq_container-10ec4732 | None | rabbitmq | infra01 | None | 172.29.239.49 | None |
Теперь можно приступить к созданию контейнера:
# openstack-ansible playbooks/lxc-containers-create.yml --limit infra01,rabbitmq
Установите RabbitMQ в новый контейнер и убедитесь, что он является частью кластера:
# openstack-ansible playbooks/rabbitmq-install.yml
После восстановления кластера стоит очистить статус кластера в отношении старого имени контейнера, которое по-прежнему считается «дисковым узлом», поскольку имя контейнера изменилось:
# ansible -m command -a "rabbitmqctl forget_cluster_node rabbit@control01-rabbit-mq-container-a3a802ac" rabbitmq[0]
Примечание
Вы можете взять имя узла кластера, которое необходимо удалить, из вывода на втором этапе.
Повторите вышеуказанные шаги для остальных инстансов.
Вариант 3: горизонтальное расширение кластеров¶
Этот вариант является наименее популярным, несмотря на свою простоту, поскольку его применение в случае, когда такой подход к масштабированию имеет смысл, довольно ограничено.
Однако, чтобы сохранить кворум, вы всегда должны иметь нечетное количество участников кластера или быть готовыми настроить дополнительную конфигурацию, если используете четное количество участников.
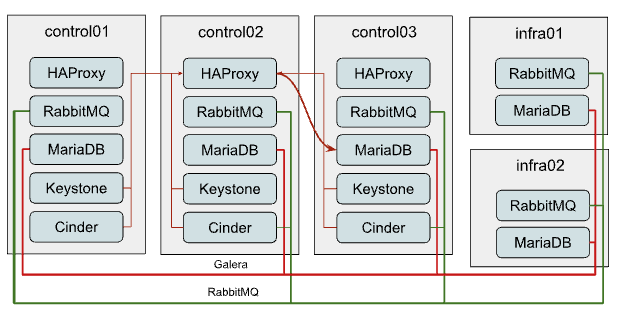
Добавление новых участников в кластер MariaDB Galera¶
Горизонтальное масштабирование кластера MariaDB имеет смысл только в том случае, если вы используете балансировщик L7, который может правильно работать с кластерами Galera (например, ProxySQL или MaxScale), а не стандартный HAProxy, и слабым местом текущего кластера является производительность чтения, а не записи.
Расширить кластер довольно просто. Для этого необходимо:
Добавьте еще один хост назначения в
openstack_user_configдля database_hosts:database_hosts: control01: ip: 172.29.236.11 control02: ip: 172.29.236.12 control03: ip: 172.29.236.13 infra01: ip: 172.29.236.21 infra02: ip: 172.29.236.22
Создайте новые контейнеры на хосте назначения:
# openstack-ansible playbooks/lxc-containers-create.yml --limit infra01,infra02,galera
Разверните MariaDB там и добавьте его в кластер:
# openstack-ansible playbooks/galera-install.yml
Убедитесь, что кластер рабочий, выполнив следующий ad-hoc:
# ansible -m command -a "mysql -e \"SHOW STATUS WHERE Variable_name IN ('wsrep_local_state_comment', 'wsrep_cluster_size', 'wsrep_incoming_addresses')\"" neutron_galera
Добавление новых участников в кластер RabbitMQ¶
Вертикальное расширение кластера RabbitMQ имеет смысл в основном в том случае, если у вас не включены очереди HA или Quorum.
Чтобы добавить больше участников в кластер RabbitMQ, выполните следующие шаги:
Добавьте еще один хост назначения в
openstack_user_configдля mq_hosts:mq_hosts: control01: ip: 172.29.236.11 control02: ip: 172.29.236.12 control03: ip: 172.29.236.13 infra01: ip: 172.29.236.21 infra02: ip: 172.29.236.22
Создайте новые контейнеры на хосте назначения:
# openstack-ansible playbooks/lxc-containers-create.yml --limit infra01,infra02,rabbitmq
Разверните RabbitMQ на новом хосте и добавьте его в кластер:
# openstack-ansible playbooks/rabbitmq-install.yml
После развертывания нового контейнера RabbitMQ необходимо перенастроить все службы, чтобы они распознавали его существование. Для этого можно запустить отдельные плейбуки для служб, например так:
# openstack-ansible playbooks/os-<service>-install.yml –tags <service>-config
Где <service> — это название службы, например neutron, nova, cinder и т. д. Другой способ — запустить файл setup-openstack.yml, но его выполнение займет довольно много времени.
Заключение¶
Как вы можете видеть, OpenStack-Ansible достаточно гибкий, чтобы позволить вам масштабировать развертывание многими различными способами.
Но какой из них подходит именно вам? Все зависит от ситуации, в которой вы находитесь.
Если ваше развертывание выросло до такой степени, что кластеры RabbitMQ/MariaDB не могут просто справиться с нагрузкой, которую создают эти кластеры, независимо от аппаратного обеспечения, на котором они работают, вам следует использовать первый вариант (Вариант 1: независимые кластеры для каждой службы) и создать независимые кластеры для каждой службы.
Этот вариант также можно рекомендовать для повышения отказоустойчивости развертывания — в случае сбоя кластера это повлияет только на одну службу, а не на все службы в общем случае развертывания. Другой довольно популярной вариацией этого варианта может быть наличие только автономных инстансов MariaDB/RabbitMQ для каждой службы без какой-либо кластеризации. Преимуществом такой настройки является очень быстрое восстановление, особенно когда речь идет о RabbitMQ.
Если у вас довольно скромные аппаратные характеристики управляющих (control) узлов, вам стоит обратить больше внимания на второй вариант (Вариант 1: независимые кластеры для каждой службы). Таким образом, вы сможете разгрузить управляющие (control) узлы, перенеся тяжелые приложения, такие как MariaDB/RabbitMQ, на другое оборудование, которое также может иметь относительно скромные характеристики.
Третий вариант (Вариант 3: горизонтальное расширение кластеров) можно использовать, если ваше развертывание соответствует требованиям, указанным выше (т. е. не использует очереди HA или ProxySQL для балансировки), и обычно его следует рассматривать, когда первый вариант уже не подходит.
